Computer Science > SOLUTIONS MANUAL > Learning Deep Learning Theory and Practice of Neural Networks, Computer Vision, Natural Language Pro (All)
Learning Deep Learning Theory and Practice of Neural Networks, Computer Vision, Natural Language Processing, and Transformers Using TensorFlow, 1st edition By Magnus Ekman (Solutions Manual )
Document Content and Description Below
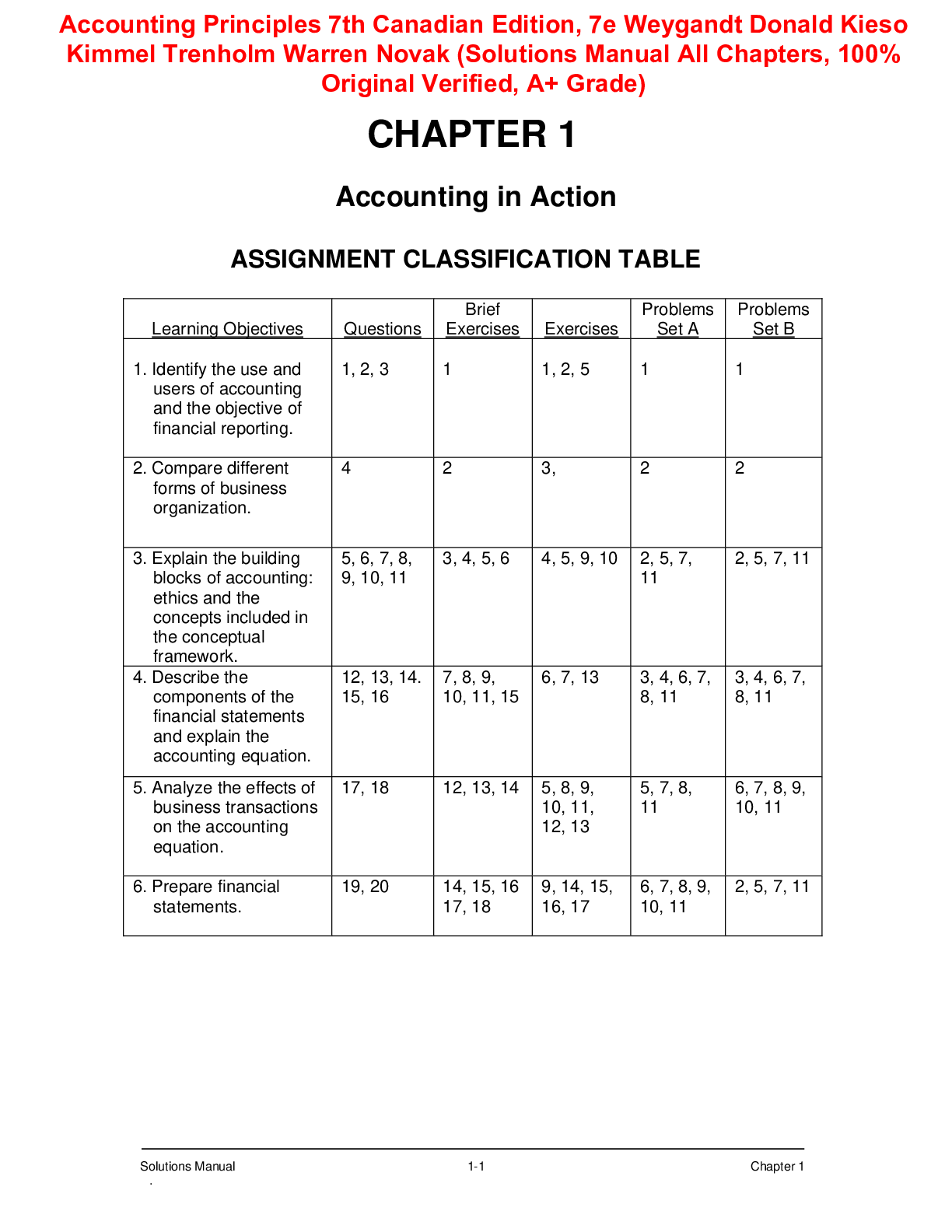
Foreword by Dr. Anima Anandkumar xxi Foreword by Dr. Craig Clawson xxiii Preface xxv Acknowledgments li About the Author liii Chapter 1: The Rosenblatt Perceptron 1 Example of a Two-Input Perc... eptron 4 The Perceptron Learning Algorithm 7 Limitations of the Perceptron 15 Combining Multiple Perceptrons 17 Implementing Perceptrons with Linear Algebra 20 Geometric Interpretation of the Perceptron 30 Understanding the Bias Term 33 Concluding Remarks on the Perceptron 34 Chapter 2: Gradient-Based Learning 37 Intuitive Explanation of the Perceptron Learning Algorithm 37 Derivatives and Optimization Problems 41 Solving a Learning Problem with Gradient Descent 44 Constants and Variables in a Network 48 Analytic Explanation of the Perceptron Learning Algorithm 49 Geometric Description of the Perceptron Learning Algorithm 51 Revisiting Different Types of Perceptron Plots 52 Using a Perceptron to Identify Patterns 54 Concluding Remarks on Gradient-Based Learning 57 Chapter 3: Sigmoid Neurons and Backpropagation 59 Modified Neurons to Enable Gradient Descent for Multilevel Networks 60 Which Activation Function Should We Use? 66 Function Composition and the Chain Rule 67 Using Backpropagation to Compute the Gradient 69 Backpropagation with Multiple Neurons per Layer 81 Programming Example: Learning the XOR Function 82 Network Architectures 87 Concluding Remarks on Backpropagation 89 Chapter 4: Fully Connected Networks Applied to Multiclass Classification 91 Introduction to Datasets Used When Training Networks 92 Training and Inference 100 Extending the Network and Learning Algorithm to Do Multiclass Classification 101 Network for Digit Classification 102 Loss Function for Multiclass Classification 103 Programming Example: Classifying Handwritten Digits 104 Mini-Batch Gradient Descent 114 Concluding Remarks on Multiclass Classification 115 Chapter 5: Toward DL: Frameworks and Network Tweaks 117 Programming Example: Moving to a DL Framework 118 The Problem of Saturated Neurons and Vanishing Gradients 124 Initialization and Normalization Techniques to Avoid Saturated Neurons 126 Cross-Entropy Loss Function to Mitigate Effect of Saturated Output Neurons 130 Different Activation Functions to Avoid Vanishing Gradient in Hidden Layers 136 Variations on Gradient Descent to Improve Learning 141 Experiment: Tweaking Network and Learning Parameters 143 Hyperparameter Tuning and Cross-Validation 146 Concluding Remarks on the Path Toward Deep Learning 150 Chapter 6: Fully Connected Networks Applied to Regression 153 Output Units 154 The Boston Housing Dataset 160 Programming Example: Predicting House Prices with a DNN 161 Improving Generalization with Regularization 166 Experiment: Deeper and Regularized Models for House Price Prediction 169 Concluding Remarks on Output Units and Regression Problems 170 Chapter 7: Convolutional Neural Networks Applied to Image Classification 171 The CIFAR-10 Dataset 173 Characteristics and Building Blocks for Convolutional Layers 175 Combining Feature Maps into a Convolutional Layer 180 Combining Convolutional and Fully Connected Layers into a Network 181 Effects of Sparse Connections and Weight Sharing 185 Programming Example: Image Classification with a Convolutional Network 190 Concluding Remarks on Convolutional Networks 201 Chapter 8: Deeper CNNs and Pretrained Models 205 VGGNet 206 GoogLeNet 210 ResNet 215 Programming Example: Use a Pretrained ResNet Implementation 223 Transfer Learning 226 Backpropagation for CNN and Pooling 228 Data Augmentation as a Regularization Technique 229 Mistakes Made by CNNs 231 Reducing Parameters with Depthwise Separable Convolutions 232 Striking the Right Network Design Balance with EfficientNet 234 Concluding Remarks on Deeper CNNs 235 Chapter 9: Predicting Time Sequences with Recurrent Neural Networks 237 Limitations of Feedforward Networks 241 Recurrent Neural Networks 242 Mathematical Representation of a Recurrent Layer 243 Combining Layers into an RNN 245 Alternative View of RNN and Unrolling in Time 246 Backpropagation Through Time 248 Programming Example: Forecasting Book Sales 250 Dataset Considerations for RNNs 264 Concluding Remarks on RNNs 265 Chapter 10: Long Short-Term Memory 267 Keeping Gradients Healthy 267 Introduction to LSTM 272 LSTM Activation Functions 277 Creating a Network of LSTM Cells 278 Alternative View of LSTM 280 Related Topics: Highway Networks and Skip Connections 282 Concluding Remarks on LSTM 282 Chapter 11: Text Autocompletion with LSTM and Beam Search 285 Encoding Text 285 Longer-Term Prediction and Autoregressive Models 287 Beam Search 289 Programming Example: Using LSTM for Text Autocompletion 291 Bidirectional RNNs 298 Different Combinations of Input and Output Sequences 300 Concluding Remarks on Text Autocompletion with LSTM 302 Chapter 12: Neural Language Models and Word Embeddings 303 Introduction to Language Models and Their Use Cases 304 Examples of Different Language Models 307 Benefit of Word Embeddings and Insight into How They Work 313 Word Embeddings Created by Neural Language Models 315 Programming Example: Neural Language Model and Resulting Embeddings 319 King − Man + Woman! = Queen 329 King − Man + Woman ! = Queen 331 Language Models, Word Embeddings, and Human Biases 332 Related Topic: Sentiment Analysis of Text 334 Concluding Remarks on Language Models and Word Embeddings 342 Chapter 13: Word Embeddings from word2vec and GloVe 343 Using word2vec to Create Word Embeddings Without a Language Model 344 Additional Thoughts on word2vec 352 word2vec in Matrix Form 353 Wrapping Up word2vec 354 Programming Example: Exploring Properties of GloVe Embeddings 356 Concluding Remarks on word2vec and GloVe 361 Chapter 14: Sequence-to-Sequence Networks and Natural Language Translation 363 Encoder-Decoder Model for Sequence-to-Sequence Learning 366 Introduction to the Keras Functional API 368 Programming Example: Neural Machine Translation 371 Experimental Results 387 Properties of the Intermediate Representation 389 Concluding Remarks on Language Translation 391 Chapter 15: Attention and the Transformer 393 Rationale Behind Attention 394 Attention in Sequence-to-Sequence Networks 395 Alternatives to Recurrent Networks 406 Self-Attention 407 Multi-head Attention 410 The Transformer 411 Concluding Remarks on the Transformer 415 Chapter 16: One-to-Many Network for Image Captioning 417 Extending the Image Captioning Network with Attention 420 Programming Example: Attention-Based Image Captioning 421 Concluding Remarks on Image Captioning 443 Chapter 17: Medley of Additional Topics 447 Autoencoders 448 Multimodal Learning 459 Multitask Learning 469 Process for Tuning a Network 477 Neural Architecture Search 482 Concluding Remarks 502 Chapter 18: Summary and Next Steps 503 Things You Should Know by Now 503 Ethical AI and Data Ethics 505 Things You Do Not Yet Know 512 Next Steps 516 Appendix A: Linear Regression and Linear Classifiers 519 Linear Regression as a Machine Learning Algorithm 519 Computing Linear Regression Coefficients 523 Classification with Logistic Regression 525 Classifying XOR with a Linear Classifier 528 Classification with Support Vector Machines 531 Evaluation Metrics for a Binary Classifier 533 Appendix B: Object Detection and Segmentation 539 Object Detection 540 Semantic Segmentation 549 Instance Segmentation with Mask R-CNN 559 Appendix C: Word Embeddings Beyond word2vec and GloVe 563 Wordpieces 564 FastText 566 Character-Based Method 567 ELMo 572 Related Work 575 Appendix D: GPT, BERT, AND RoBERTa 577 GPT 578 BERT 582 RoBERTa 586 Historical Work Leading Up to GPT and BERT 588 Other Models Based on the Transformer 590 Appendix E: Newton-Raphson versus Gradient Descent 593 Newton-Raphson Root-Finding Method 594 Relationship Between Newton-Raphson and Gradient Descent 597 Appendix F: Matrix Implementation of Digit Classification Network 599 Single Matrix 599 Mini-Batch Implementation 602 Appendix G: Relating Convolutional Layers to Mathematical Convolution 607 Appendix H: Gated Recurrent Units 613 Alternative GRU Implementation 616 Network Based on the GRU 616 Appendix I: Setting up a Development Environment 621 Python 622 Programming Environment 623 Programming Examples 624 Datasets 625 Installing a DL Framework 628 TensorFlow Specific Considerations 630 Key Differences Between PyTorch and TensorFlow 631 Appendix J: Cheat Sheets 637 Works Cited 647 Index 667 [Show More]
Last updated: 1 year ago
Preview 1 out of 119 pages
Reviews( 0 )
Document information
Connected school, study & course
About the document
Uploaded On
Nov 19, 2022
Number of pages
119
Written in

Additional information
This document has been written for:
Uploaded
Nov 19, 2022
Downloads
0
Views
124






, 2e by Stephen Lovett.png)







 2e Peter Olver, Chehrzad Shakiban.png)



















