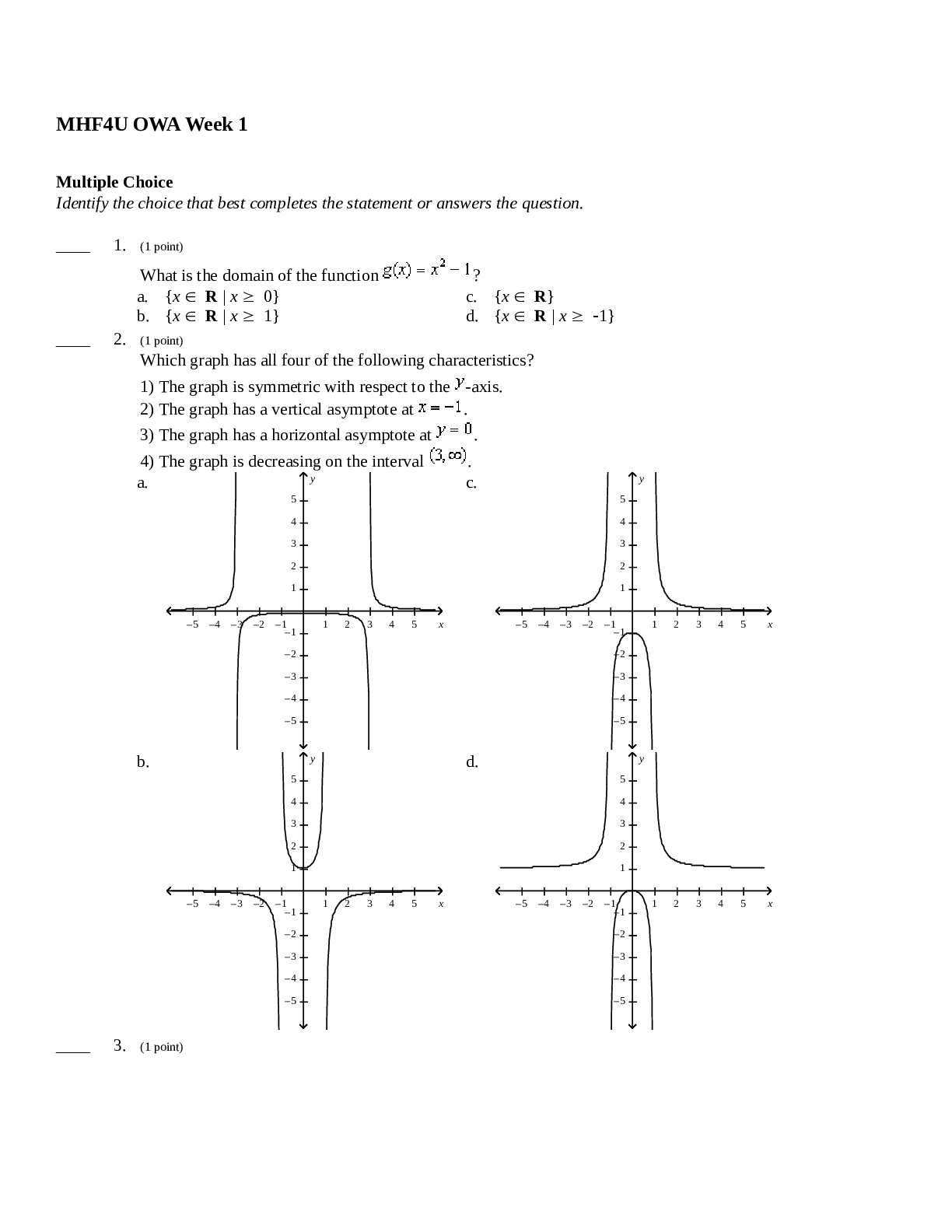Computer Science > QUESTION PAPER (QP) > Columbia University - CS 4111database_2014 (All)
Columbia University - CS 4111database_2014
Document Content and Description Below
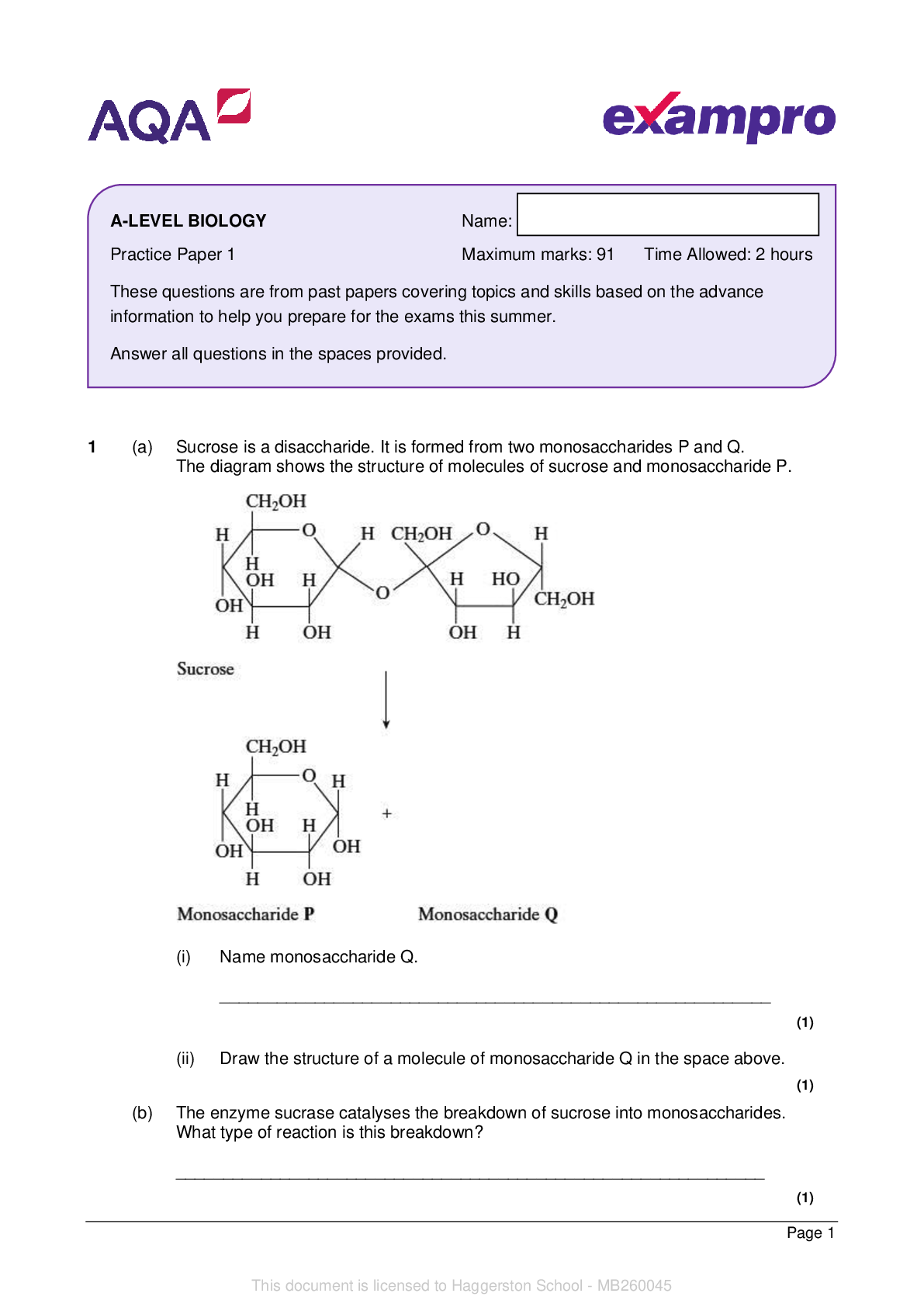
W4111 Database Systems, Section 2 Fall 2014 Homework 3, due 11/13/2014. 1. The UCSC genome browser uses an underlying MySQL database; the schema can be browsed if you are interested (not required)... at http://genome.ucsc.edu/cgi-bin/hgTables. One table called “knownGene” records genes and their names, positions, etc. within the genome. Within this table are two “longblob” type attributes called exonStarts and exonEnds. Each entry within these lists corresponds to the start and end position of an exon within the gene. (A gene can contain many exons, which are distinct contiguous regions of DNA sequence. Exons are the protein-coding part of genes.) The longblob types are recorded as strings containing the list of integer positions separated by commas. We would like to be able to: • Check that the exonStarts and exonEnds attributes are well-formed (i.e., that they are integers separated by commas). • Check that the number of exonStart positions is the same as the number of exonEnd positions. • Query the data, e.g., ask what the total length of all the exons is, or how many exons the gene contains. (a) Critique this design. Explain why the constraints and queries mentioned above are hard (or impossible) to specify in standard SQL. (b) MySQL lacks many object-relational features. Use Oracle’s nested-table feature (see e.g., http://www.orafaq.com/wiki/NESTED_TABLE) to propose an alternative object-relational design for representing the same information about exons. (c) Show how the nested-table feature enables a straightforward expression of the queries and constraints. 2. Imagine the US Tax Department stores information about every taxpayer in a large relational database. Suppose that the main data is stored in a table Taxpayer(SSN,Tax-year,Name,Zipcode,Total-income,Total-tax,Date-filed,Num-dependents) The database contains information about 108 taxpayers, each for an average of 10 tax years, so there are 109 rows in the table. You may assume that all numeric and date fields occupy 8 bytes, and that names are, on average, 24 bytes long. The data is stored on a disk device with a block size of 4KB, and rows do not span more than one block. You may assume that RIDs and internal tree pointers are 8 bytes. The data is appended to the table (stored as a heap file) as each tax return is filed. There is a hash-index on (SSN,Tax-year) which constitutes the primary key, a B+ tree index on Totalincome, and a B+ tree index on the pair (Zipcode,Name). (a) Estimate the branching factor F and the depth of the B+ tree index on Total-income. You may assume that nodes are 2/3 full. (b) What is the I/O cost to scan the whole table? (c) What is the total I/O cost to append a new record? State clearly any assumptions you make about the behavior of the buffer pool. (d) Suppose that a tax department employee wants to execute the query Select * from Taxpayer where Total-income > t for some threshold t. If the selectivity corresponding to this condition is 4% (so that only 4% of taxpayers have income more than t) would the database system use the index on Total-income to access the data? Be quantitative. (e) Suppose that a tax department employee wants to execute the query 1 [Show More]
Last updated: 1 year ago
Preview 1 out of 2 pages

Reviews( 0 )
Document information
Connected school, study & course
About the document
Uploaded On
Mar 28, 2021
Number of pages
2
Written in

Additional information
This document has been written for:
Uploaded
Mar 28, 2021
Downloads
0
Views
96







.png)