Data Mining > EXAM > DATA MINING 550: Final Exam. 40 Questions and Answers. All the correct answers are indicated. (All)
DATA MINING 550: Final Exam. 40 Questions and Answers. All the correct answers are indicated.
Document Content and Description Below
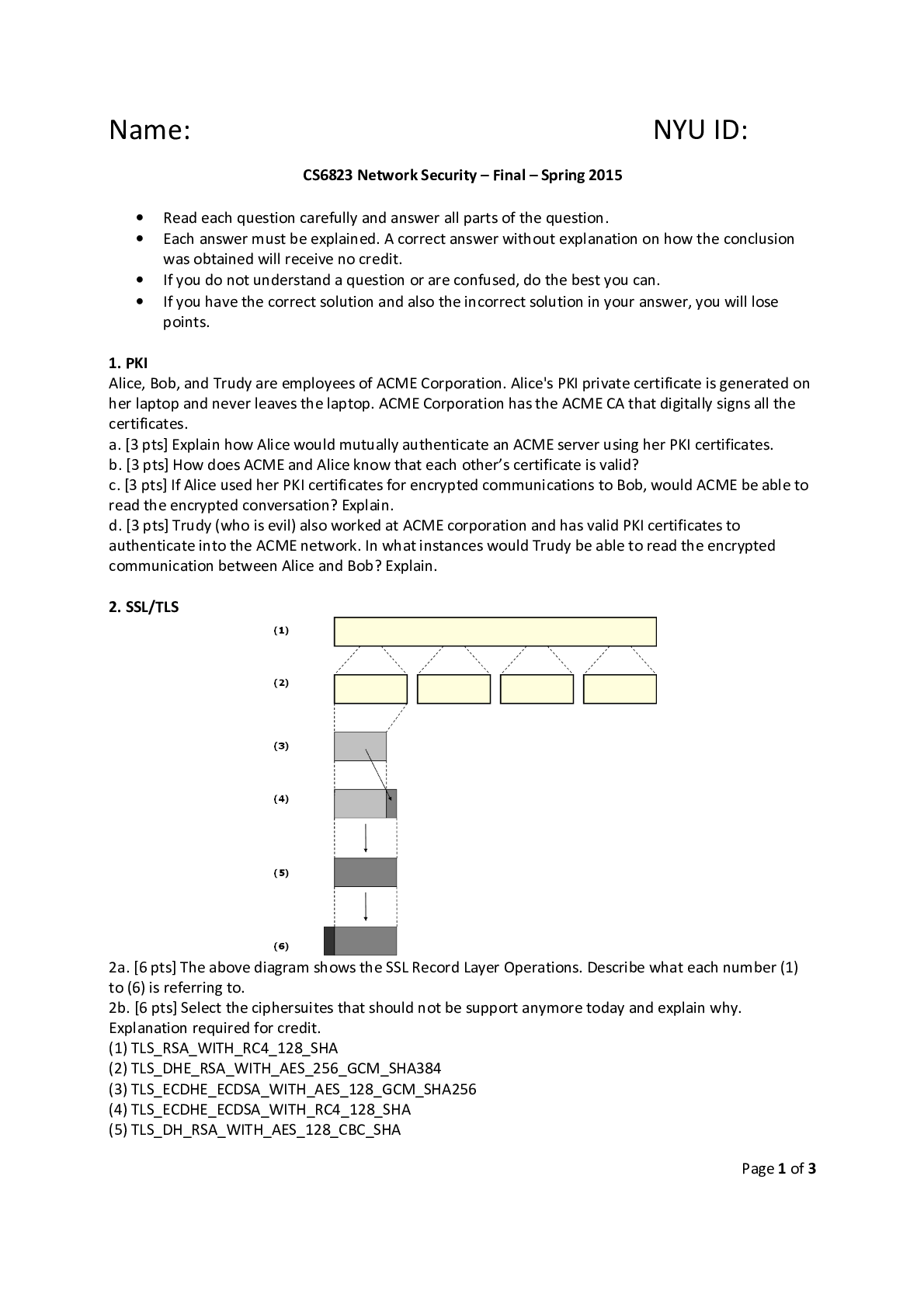
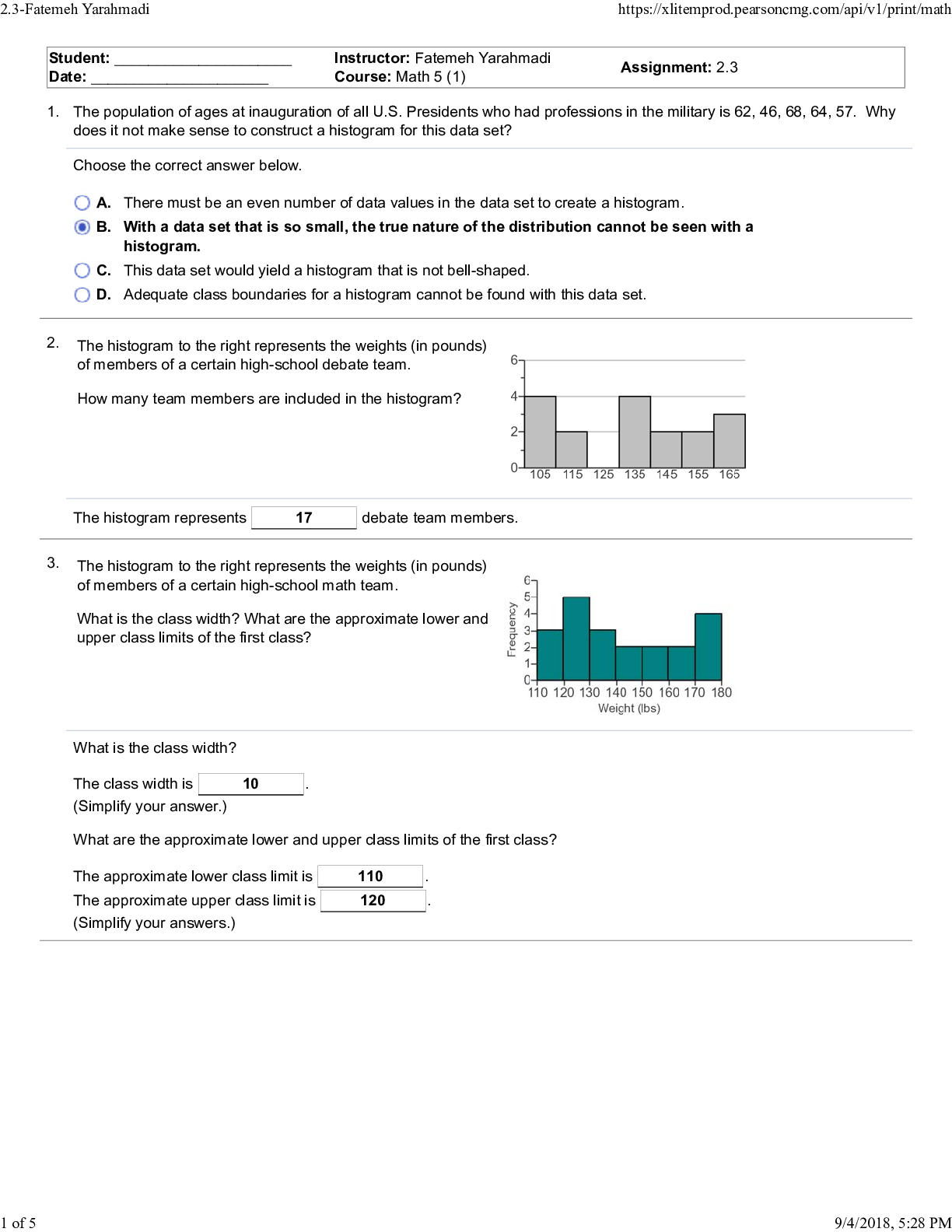
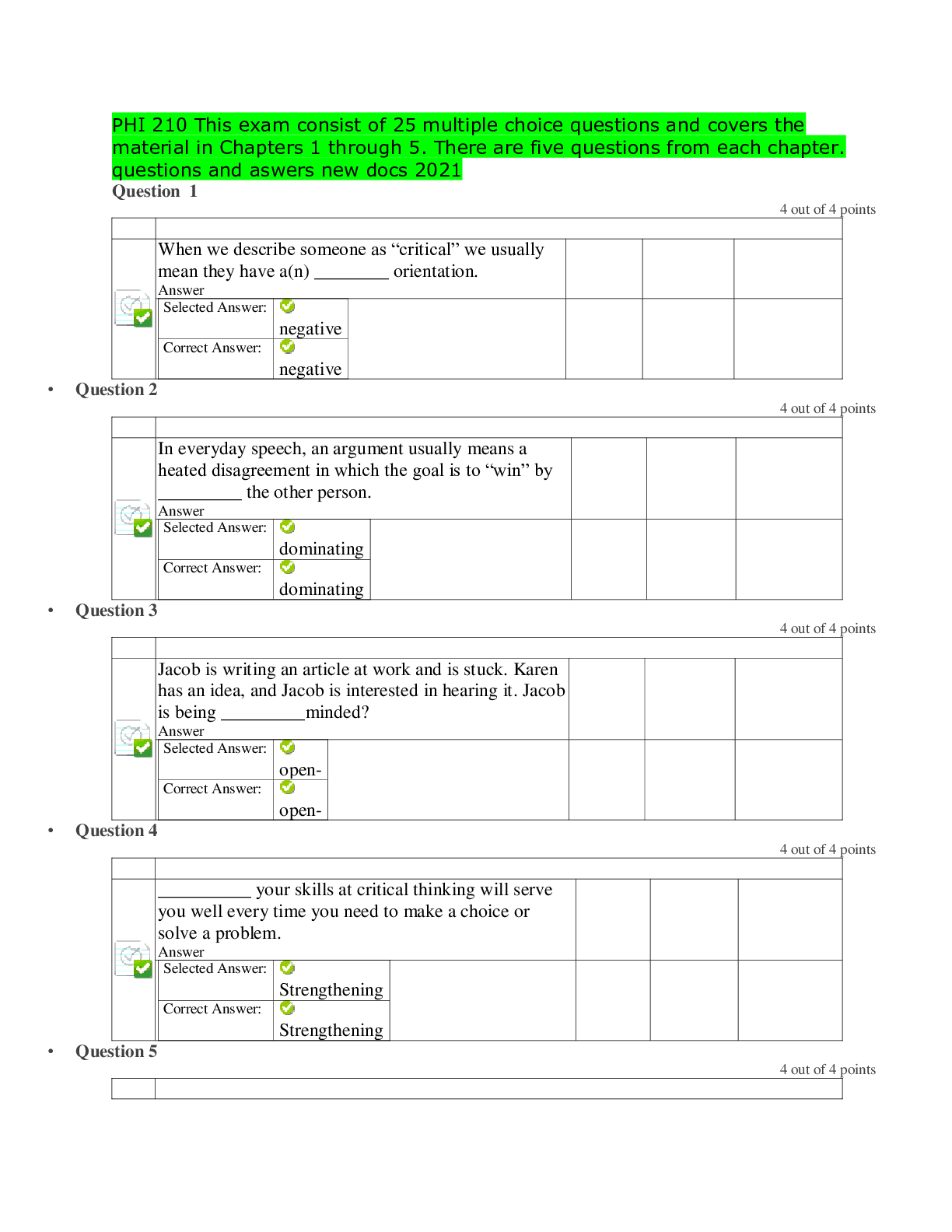
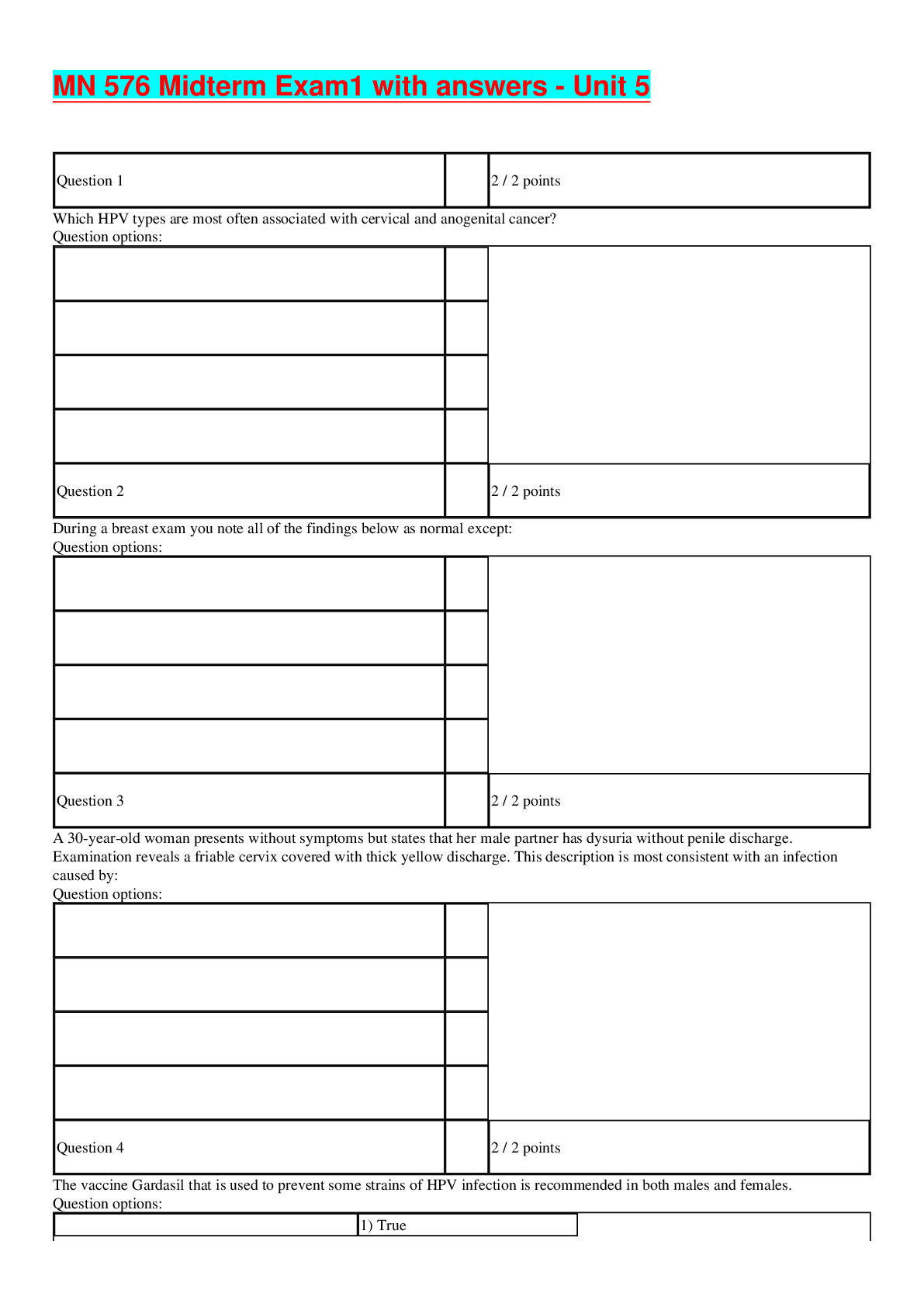
DATA MINING 550: Final quiz Points Missed 1.00 Percentage 97.5% 1. A drawback of the k-NN method is that the _________. A) method does not support prediction B) method can be used to cla... ssify only two classes C) relationship between the dependent variable and the predictor variables must be linear D) required size of the training set increases exponentially with the number of predictors 1.0/1.0 D 2. In k-NN the most common method of determine the best value of “k” is to _________. A) use the value that has the lowest error rate when applied to the training data B) use the value that has the lowest error rate when applied to the validation data C) set k = 1 so that the method with computing quickly D) set k = n where “n” is the number of cases in the dataset 1.0/1.0 B 3. To equalize the scales that the various predictors may have, predictors should be ________ prior to using the k-NN method. A) partitioned B) smoothed C) standardized D) verified 1.0/1.0 C 4. The method k-nearest neighbors can be used for _________. A) classification only B) prediction only C) both classification and prediction D) neither classifiation nor prediction 1.0/1.0 C 5. An advantage of the k-NN method is ________. A) simplicity B) that there are no assumptions requiring the distribution of the data C) c. that it is effective at capturing complex interactions among variables without having to define a statistical model D) All of the above. 1.0/1.0 D 6. In k-NN the default classification cutoff value is _________. A) 0.5 B) 0.6 C) 0.7 D) equal to the classification accuracy rate achieved with the validation data 1.0/1.0 A 7. Using k-NN for prediction provides ________. A) a numerical outcome only B) a classification outcome only C) either a numerical or classification outcome D) neither a numerical nor classification outcome 1.0/1.0 A 8. In k-NN which of the following statements describes characteristics of low values of k? A) They provide more smoothing, more noise, and capture local structure in the data. B) They provide more smoothing, less noise, but may miss local structure. C) They capture local structure in the data, but also may include noise. D) They capture local structure in data, less smoothing, and less noise. 1.0/1.0 C 9. In k-NN which of the following statements describes characteristics of high values of k? A) They provide more smoothing, more noise, and capture local structure in the data. B) They provide more smoothing, less noise, but may miss local structure. C) They capture local structure in the data, but also may include noise. D) They capture local structure in data, less smoothing, and less noise. 1.0/1.0 B 10. In a k-NN classification model where k is equal to the number of records in the training data, which of the following statements is FALSE? A) The classification rule is equivalent to the naïve (majority) rule. B) None of the information of the predictor variables will affect the classifications. C) The resulting k-NN model will be of no value to the data miner. D) None of the above. 1.0/1.0 D 11. The naïve Bayes method can be used for _________. A) classification only B) prediction only C) both classification and prediction D) neither classifiation and prediction 1.0/1.0 A 12. The naïve Bayes method can be used with which of the following types of data. A) Categorical only B) Numeric only C) Both categorical and numeric D) Normalized 1.0/1.0 A 13. When using the basic naïve Bayes method, we assign a new (unclassified) record to the class with ________. A) the highest probability for this set of predictor values B) the lowest probability for this set of predictor values C) a probability greater than 0.5 D) a probability greater than 0.5 1.0/1.0 A 14. The Naïve Bayes method can be used for the purpose(s) of ________. A) classification only B) prediction only C) both classification and prediction D) None of the above 1.0/1.0 A 15. The method that uses only records from the validation dataset that are identical matches on the predictors to the record to be classified is known as the _________ method. A) k-NN B) naïve Bayes classifier C) full (exact) Bayesian classifier D) multiple regression 1.0/1.0 C 16. Assume two independent events A and B with probabilities of P(A) and P(B), respectively. What is the probability of the combined event of A and B? A) P(A) + P(B). B) P(A) x P(B). C) (P(A) + P(B)) / 2. D) P(A + B). 1.0/1.0 B 17. Which of the following are advantages of the naïve Bayes method? A) It handles purely categorical data well. B) It works well with very large datasets. C) It's conceptually simple and computationally efficient D) All of the above. 1.0/1.0 D 18. The main weakness of the full (exact) Bayesian classifier is _________. A) the requirement that the predictors must be independent of each other B) the very large validation set that will be needed when there are many predictors C) that all the records in the validation set must be used in the computation D) that the cutoff probability must be set at 0.5 1.0/1.0 B 19. Suppose you have a validation dataset and you want to use the naïve Bayes method to classify a new record. But one of the key predictors is numeric. What should you do? A) Drop the numeric predictor and use the naïve Bayes method on the other predictors. B) Select another method, since the naïve Bayes method cannot be used in this case. C) Convert the numeric variable into a categorical variable by binning, and then use the naïve Bayes method in the usual way. D) Use the full (exact) Bayesian classifier instead. 1.0/1.0 C 20. Which of the following statements is true about the naïve Bayes method? A) It can be used with numeric data only. B) It is an unsupervised method. C) It is a model driven approach to data mining. D) None of the above 1.0/1.0 D 21. The main problem with overfitting is that it________. A) leads to low predictive accuracy of new data B) is a waste of resources C) is computationally complex D) None of the above. 1.0/1.0 A 22. Which of the following statements is true of using regression trees for prediction? A) It is used with continuous outcome variables. B) The procedure is similar to classification trees. C) The goal of the procedure is to find the split that minimizes impurity. D) All of the above. 1.0/1.0 D 23. Which of the following is an advantage of using the “classification and regression tree” (CART) data mining method? A) It produces rules that are easy to interpret & implement. B) It does not require the assumptions of statistical models C) It does not require the assumptions of statistical models D) All of the above. 1.0/1.0 D 24. The process in which repeatedly splits of records into two parts so as to achieve maximum homogeneity within the new parts is known as _________. A) pruning B) performance evaluation C) recursive partitioning D) regression trees for prediction 1.0/1.0 C 25. Consider the following decision rule: IF (AGE > 50) AND (INCOME ≤ 80,000) AND (OWN_HOME = “NO”) THEN CLASS = 0. How many nodes of a decision tree must be passed through to arrive at this rule? A) 1 B) 2 C) 3 D) It depends on how it is structured 1.0/1.0 C 26. When the recursive partitioning process is applied to the training data and is allowed to run to its end, the resulting tree ________. A) is the final solution to the problem B) has a misclassification rate of 0 C) does not have any overfitting problems D) is ready to be used on the validation data 1.0/1.0 B 27. When there is no class of special interest, the classification of a new record is determined ________. A) by majority vote B) at random C) by a cutoff point D) by a domain expert 1.0/1.0 A 28. Which of the following statements is NOT true of the value that appears inside a binary decision tree node? A) It is the value that results in the split having the minimum impurity. B) It is the midpoint of the distribution of values of the variable. C) It is a splitting point that determines which path will be followed. D) None of the above. 1.0/1.0 B 29. The value that is inside the rectangle of a terminal leaf of a classification tree represents the ________. A) number of records in the training data that followed that path B) splitting point of the distribution of values of the variable C) average of the variable D) class to which a new record that followed that path will be assigned 1.0/1.0 D 30. In the recursive partitioning process, how can the problem of overfitting be managed? A) Set rules to stop tree grown before overfitting sets in. B) Prune the full-grown tree back to a level where overfitting is no longer a problem. C) Both (a) and (b). D) Neither (a) or (b). 1.0/1.0 C 31. Which of the following statements is true about affinity analysis? A) It is a supervised method. B) Variables must be normalized prior to analysis. C) The primary result of the analysis is an equation that can be used for prediction. D) None of the above. 0.0/1.0 D 32. In the association rules method, the records of a dataset are commonly converted to __________ prior to analysis. A) third normal form B) pivot tables C) common logarithms D) binary matrix format 1.0/1.0 D 33. In the association rules method, a lift ratio of _________ indicated that the antecedent and consequent of a rule have no relationship beyond that of chance. A) 0 B) 1 C) ≤ 0 D) ≤ 1 1.0/1.0 B 34. In the association rules method, the goal of rule selection is to find _________. A) rules that have a high level of support B) rules that have a high level of confidence C) only the rules that indicate a strong dependence between the antecedent and consequent item sets D) All of the above. 1.0/1.0 C 35. In the association rules method, the confidence and lift ratio are used to measure the _________ of a rule. A) strength B) support C) validity D) purity 1.0/1.0 A 36. In the association rule method the support and confidence cutoff criteria percents for rule section determined _________. A) at random B) by the Apriory algorithm C) by the data miner D) by the size of the dataset 1.0/1.0 C 37. In the association rules method, the most common procedure for generating frequent item sets is _________. A) the Apriori algorithm B) the Gini Index C) the simplex method D) recursive partitioning 1.0/1.0 A 38. Which of the following statements is true of the antecedent and consequent of a rule? A) The item sets of the two can be interchanged (swapped) without affecting the meaning of the rule. B) The consequent may have only one item, while the antecedent may have many. C) They have no items in common (disjoint). D) None of the above. 1.0/1.0 C 39. Market basket analysis is commonly used in _________ systems. A) election polling B) recommender C) inventory control D) poulation demographic 1.0/1.0 B 40. The form of an association rule is expressed in two parts called the _________ and the _________. A) subject; object B) primary; secondary C) antecedent; consequent D) condition; action 1.0/1.0 C Points Awarded 38.00 Points Missed 2.00 Percentage 95.0% 1. The method k-nearest neighbors can be used for _________. A) classification only B) prediction only C) both classification and prediction D) neither classifiation nor prediction 0.0/1.0 C 2. An advantage of the k-NN method is ________. A) simplicity B) that there are no assumptions requiring the distribution of the data C) c. that it is effective at capturing complex interactions among variables without having to define a statistical model D) All of the above. 1.0/1.0 D 3. The sharp increase in the required size of the training set with the increase in the number of predictors is referred to as ________. A) overfitting to the noise B) the loss of local structure due to over smoothing C) the curse of dimensionality D) None of the above 1.0/1.0 C 4. To equalize the scales that the various predictors may have, predictors should be ________ prior to using the k-NN method. A) partitioned B) smoothed C) standardized D) verified 1.0/1.0 C 5. In k-NN the default classification cutoff value is _________. A) 0.5 B) 0.6 C) 0.7 D) equal to the classification accuracy rate achieved with the validation data 1.0/1.0 A 6. In a k-NN classification model where k is equal to the number of records in the training data, which of the following statements is FALSE? A) The classification rule is equivalent to the naïve (majority) rule. B) None of the information of the predictor variables will affect the classifications. C) The resulting k-NN model will be of no value to the data miner. D) None of the above. 1.0/1.0 D 7. In k-NN which of the following statements describes characteristics of high values of k? A) They provide more smoothing, more noise, and capture local structure in the data. B) They provide more smoothing, less noise, but may miss local structure. C) They capture local structure in the data, but also may include noise. D) They capture local structure in data, less smoothing, and less noise. 1.0/1.0 B 8. In k-NN for prediction ________. A) cannot be done B) can be done with the use of majority voting to determine class C) can be done with the use of weighted averages with weights decreasing as distance increases D) can be done when the outcome variable is categorical 1.0/1.0 C 9. The “k” in k-nearest neighbors refers to the number of _________. A) variables that will be used by the k-NN methods B) records that will be used by the k-NN methods C) records in the training data D) records in the validation data 1.0/1.0 B 10. A drawback of the k-NN method is that the _________. A) method does not support prediction B) method can be used to classify only two classes C) relationship between the dependent variable and the predictor variables must be linear D) required size of the training set increases exponentially with the number of predictors 1.0/1.0 D 11. A shortcoming of the naïve Bayes method is ________. A) its simplicity B) its computatinally efficient C) that all records are used in the calculation D) the possibility that a predictor category is not present in the training data 1.0/1.0 D 12. Which of the following statements is true about the naïve Bayes method? A) It can be used with numeric data only. B) It is an unsupervised method. C) It is a model driven approach to data mining. D) None of the above 1.0/1.0 D 13. Assume two independent events A and B with probabilities of P(A) and P(B), respectively. What is the probability of the combined event of A and B? A) P(A) + P(B). B) P(A) x P(B). C) (P(A) + P(B)) / 2. D) P(A + B). 1.0/1.0 B 14. In the naïve Bayes method, the notation P(A|B) means _________. A) P multiplied by the quotient of A and B B) P is a function of variables A and B C) The probability of A given that B is true D) None of the above. 1.0/1.0 C 15. The naïve Bayes method can be used with which of the following types of data. A) Categorical only B) Numeric only C) Both categorical and numeric D) Normalized 1.0/1.0 A 16. The method that uses only records from the validation dataset that are identical matches on the predictors to the record to be classified is known as the _________ method. A) k-NN B) naïve Bayes classifier C) full (exact) Bayesian classifier D) multiple regression 1.0/1.0 C 17. When there is an outcome class of special interest to the data miner, it is a good idea to establish a ________ for the purpose of classifying a new record. A) weight B) model C) method D) cutoff probability 0.0/1.0 D 18. Suppose you have a validation dataset and you want to use the naïve Bayes method to classify a new record. But one of the key predictors is numeric. What should you do? A) Drop the numeric predictor and use the naïve Bayes method on the other predictors. B) Select another method, since the naïve Bayes method cannot be used in this case. C) Convert the numeric variable into a categorical variable by binning, and then use the naïve Bayes method in the usual way. D) Use the full (exact) Bayesian classifier instead. 1.0/1.0 C 19. The main weakness of the full (exact) Bayesian classifier is _________. A) the requirement that the predictors must be independent of each other B) the very large validation set that will be needed when there are many predictors C) that all the records in the validation set must be used in the computation D) that the cutoff probability must be set at 0.5 1.0/1.0 B 20. The naïve Bayes method differs from the full (exact) Bayesian classifier in that the ________. A) naïve Bayes method uses only part of the records in the dataset while the full (exact) Bayesian classifier uses all the records in the dataset B) full (exact) Bayesian classifier uses only part of the records in the data set while the naïve Bayes method uses all the records in the dataset C) There are none significant differences between the two methods. D) None of the above. 1.0/1.0 B 21. The CART method can be used for _________. A) classification only B) prediction only C) both classification and prediction D) neither classification nor prediction 1.0/1.0 C 22. The value that is inside the rectangle of a terminal leaf of a classification tree represents the ________. A) number of records in the training data that followed that path B) splitting point of the distribution of values of the variable C) average of the variable D) class to which a new record that followed that path will be assigned 1.0/1.0 D 23. When the recursive partitioning process is applied to the training data and is allowed to run to its end, the resulting tree ________. A) is the final solution to the problem B) has a misclassification rate of 0 C) does not have any overfitting problems D) is ready to be used on the validation data 1.0/1.0 B 24. Which of the following statements is true of using regression trees for prediction? A) It is used with continuous outcome variables. B) The procedure is similar to classification trees. C) The goal of the procedure is to find the split that minimizes impurity. D) All of the above. 1.0/1.0 D 25. The terminal point in a path of a tree is referred to as a _________. A) leaf B) station C) root D) branch 1.0/1.0 A 26. Which of the following is an advantage of using the “classification and regression tree” (CART) data mining method? A) It produces rules that are easy to interpret & implement. B) It does not require the assumptions of statistical models C) It does not require the assumptions of statistical models D) All of the above. 1.0/1.0 D 27. When there is no class of special interest, the classification of a new record is determined ________. A) by majority vote B) at random C) by a cutoff point D) by a domain expert 1.0/1.0 A 28. The main problem with overfitting is that it________. A) leads to low predictive accuracy of new data B) is a waste of resources C) is computationally complex D) None of the above. 1.0/1.0 A 29. The process in which repeatedly splits of records into two parts so as to achieve maximum homogeneity within the new parts is known as _________. A) pruning B) performance evaluation C) recursive partitioning D) regression trees for prediction 1.0/1.0 C 30. Which of the following statements is NOT true of the value that appears inside a binary decision tree node? A) It is the value that results in the split having the minimum impurity. B) It is the midpoint of the distribution of values of the variable. C) It is a splitting point that determines which path will be followed. D) None of the above. 1.0/1.0 B 31. In the association rule method the support and confidence cutoff criteria percents for rule section determined _________. A) at random B) by the Apriory algorithm C) by the data miner D) by the size of the dataset 1.0/1.0 C 32. The form of an association rule is expressed in two parts called the _________ and the _________. A) subject; object B) primary; secondary C) antecedent; consequent D) condition; action 1.0/1.0 C 33. In the association rules method, the confidence and lift ratio are used to measure the _________ of a rule. A) strength B) support C) validity D) purity 1.0/1.0 A 34. Which of the following is a true statement about the association rules method? A) Its output variable must be binary. B) It can only be used for classification C) It can only be used for prediction. D) It is an unsupervised learning method. 1.0/1.0 D 35. Which of the following statements is true of the antecedent and consequent of a rule? A) The item sets of the two can be interchanged (swapped) without affecting the meaning of the rule. B) The consequent may have only one item, while the antecedent may have many. C) They have no items in common (disjoint). D) None of the above. 1.0/1.0 C 36. In the association rules method, the most common procedure for generating frequent item sets is _________. A) the Apriori algorithm B) the Gini Index C) the simplex method D) recursive partitioning 1.0/1.0 A 37. Market basket analysis is commonly used in _________ systems. A) election polling B) recommender C) inventory control D) poulation demographic 1.0/1.0 B 38. In the association rules method, the records of a dataset are commonly converted to __________ prior to analysis. A) third normal form B) pivot tables C) common logarithms D) binary matrix format 1.0/1.0 D 39. In the association rules method, a lift ratio of _________ indicated that the antecedent and consequent of a rule have no relationship beyond that of chance. A) 0 B) 1 C) ≤ 0 D) ≤ 1 1.0/1.0 B 40. Another term for the “association rules” method is __________. A) cluster analysis B) affinity analysis C) correlation matrix D) neural nets 1.0/1.0 B Points Awarded 40.00 Points Missed 0.00 Percentage 100% 1. To equalize the scales that the various predictors may have, predictors should be ________ prior to using the k-NN method. A) partitioned B) smoothed C) standardized D) verified 1.0/1.0 C 2. The “k” in k-nearest neighbors refers to the number of _________. A) variables that will be used by the k-NN methods B) records that will be used by the k-NN methods C) records in the training data D) records in the validation data 1.0/1.0 B 3. The sharp increase in the required size of the training set with the increase in the number of predictors is referred to as ________. A) overfitting to the noise B) the loss of local structure due to over smoothing C) the curse of dimensionality D) None of the above 1.0/1.0 C 4. In k-NN a drawback to setting k = 1 is that _________. A) this is too few cases to accurately represent the entire dataset B) there is the danger of overfitting to the noise C) this is equivalent to the naïve (majority) rule D) None of the above 1.0/1.0 B 5. In k-NN which of the following statements describes characteristics of high values of k? A) They provide more smoothing, more noise, and capture local structure in the data. B) They provide more smoothing, less noise, but may miss local structure. C) They capture local structure in the data, but also may include noise. D) They capture local structure in data, less smoothing, and less noise. 1.0/1.0 B 6. In k-NN for prediction ________. A) cannot be done B) can be done with the use of majority voting to determine class C) can be done with the use of weighted averages with weights decreasing as distance increases D) can be done when the outcome variable is categorical 1.0/1.0 C 7. Using k-NN for prediction provides ________. A) a numerical outcome only B) a classification outcome only C) either a numerical or classification outcome D) neither a numerical nor classification outcome 1.0/1.0 A 8. A drawback of the k-NN method is that the _________. A) method does not support prediction B) method can be used to classify only two classes C) relationship between the dependent variable and the predictor variables must be linear D) required size of the training set increases exponentially with the number of predictors 1.0/1.0 D 9. In k-NN which of the following statements describes characteristics of low values of k? A) They provide more smoothing, more noise, and capture local structure in the data. B) They provide more smoothing, less noise, but may miss local structure. C) They capture local structure in the data, but also may include noise. D) They capture local structure in data, less smoothing, and less noise. 1.0/1.0 C 10. In a k-NN classification model where k is equal to the number of records in the training data, which of the following statements is FALSE? A) The classification rule is equivalent to the naïve (majority) rule. B) None of the information of the predictor variables will affect the classifications. C) The resulting k-NN model will be of no value to the data miner. D) None of the above. 1.0/1.0 D 11. The Naïve Bayes method can be used for the purpose(s) of ________. A) classification only B) prediction only C) both classification and prediction D) None of the above 1.0/1.0 A 12. Which of the following statements is true about the naïve Bayes method? A) It can be used with numeric data only. B) It is an unsupervised method. C) It is a model driven approach to data mining. D) None of the above 1.0/1.0 D 13. The main weakness of the full (exact) Bayesian classifier is _________. A) the requirement that the predictors must be independent of each other B) the very large validation set that will be needed when there are many predictors C) that all the records in the validation set must be used in the computation D) that the cutoff probability must be set at 0.5 1.0/1.0 B 14. Probability rankings of the outcome classes are generally________ the actual probability estimates. A) less accurate than B) equally accurate to C) more accurate than D) There is not particular pattern of accuracy 1.0/1.0 C 15. The naïve Bayes method differs from the full (exact) Bayesian classifier in that the ________. A) naïve Bayes method uses only part of the records in the dataset while the full (exact) Bayesian classifier uses all the records in the dataset B) full (exact) Bayesian classifier uses only part of the records in the data set while the naïve Bayes method uses all the records in the dataset C) There are none significant differences between the two methods. D) None of the above. 1.0/1.0 B 16. Suppose you have a validation dataset and you want to use the naïve Bayes method to classify a new record. But one of the key predictors is numeric. What should you do? A) Drop the numeric predictor and use the naïve Bayes method on the other predictors. B) Select another method, since the naïve Bayes method cannot be used in this case. C) Convert the numeric variable into a categorical variable by binning, and then use the naïve Bayes method in the usual way. D) Use the full (exact) Bayesian classifier instead. 1.0/1.0 C 17. In the naïve Bayes method, the notation P(A|B) means _________. A) P multiplied by the quotient of A and B B) P is a function of variables A and B C) The probability of A given that B is true D) None of the above. 1.0/1.0 C 18. Which of the following are advantages of the naïve Bayes method? A) It handles purely categorical data well. B) It works well with very large datasets. C) It's conceptually simple and computationally efficient D) All of the above. 1.0/1.0 D 19. When there is an outcome class of special interest to the data miner, it is a good idea to establish a ________ for the purpose of classifying a new record. A) weight B) model C) method D) cutoff probability 1.0/1.0 D 20. The naïve Bayes method can be used for _________. A) classification only B) prediction only C) both classification and prediction D) neither classifiation and prediction 1.0/1.0 A 21. The CART method can be used for _________. A) classification only B) prediction only C) both classification and prediction D) neither classification nor prediction 1.0/1.0 C 22. Which of the following statements is NOT true of the value that appears inside a binary decision tree node? A) It is the value that results in the split having the minimum impurity. B) It is the midpoint of the distribution of values of the variable. C) It is a splitting point that determines which path will be followed. D) None of the above. 1.0/1.0 B 23. Consider the following decision rule: IF (AGE > 50) AND (INCOME ≤ 80,000) AND (OWN_HOME = “NO”) THEN CLASS = 0. How many nodes of a decision tree must be passed through to arrive at this rule? A) 1 B) 2 C) 3 D) It depends on how it is structured 1.0/1.0 C 24. The process in which repeatedly splits of records into two parts so as to achieve maximum homogeneity within the new parts is known as _________. A) pruning B) performance evaluation C) recursive partitioning D) regression trees for prediction 1.0/1.0 C 25. Which of the following is NOT true of pruning? A) The idea is to find that point at which the validation error begins to rise. B) The pruning process usually results in the loss of important information. C) It generates successively smaller trees by pruning leaves. D) The cost complexity formula is used to choose the best tree at each stage. 1.0/1.0 B 26. The Gini Index ________. A) is used to measure predictive accuracy B) is used to measure impurity C) is scored on a scale of 0 to 100 D) requires that the data set be normalized before it can be used 1.0/1.0 B 27. The terminal point in a path of a tree is referred to as a _________. A) leaf B) station C) root D) branch 1.0/1.0 A 28. The value that is inside the rectangle of a terminal leaf of a classification tree represents the ________. A) number of records in the training data that followed that path B) splitting point of the distribution of values of the variable C) average of the variable D) class to which a new record that followed that path will be assigned 1.0/1.0 D 29. When the recursive partitioning process is applied to the training data and is allowed to run to its end, the resulting tree ________. A) is the final solution to the problem B) has a misclassification rate of 0 C) does not have any overfitting problems D) is ready to be used on the validation data 1.0/1.0 B 30. The main problem with overfitting is that it________. A) leads to low predictive accuracy of new data B) is a waste of resources C) is computationally complex D) None of the above. 1.0/1.0 A 31. Another term for the “association rules” method is __________. A) cluster analysis B) affinity analysis C) correlation matrix D) neural nets 1.0/1.0 B 32. In the association rule method the support and confidence cutoff criteria percents for rule section determined _________. A) at random B) by the Apriory algorithm C) by the data miner D) by the size of the dataset 1.0/1.0 C 33. In the association rules method, the records of a dataset are commonly converted to __________ prior to analysis. A) third normal form B) pivot tables C) common logarithms D) binary matrix format 1.0/1.0 D 34. Which of the following is a true statement about the association rules method? A) Its output variable must be binary. B) It can only be used for classification C) It can only be used for prediction. D) It is an unsupervised learning method. 1.0/1.0 D 35. In the association rules method, one approach to reducing the number of spurious rules due to chance effects is to ________. A) use a large dataset B) decrease the cutoff criteria for selection C) convert the data to binary matrix format D) normalize the data 1.0/1.0 A 36. Which of the following statements is true of the antecedent and consequent of a rule? A) The item sets of the two can be interchanged (swapped) without affecting the meaning of the rule. B) The consequent may have only one item, while the antecedent may have many. C) They have no items in common (disjoint). D) None of the above. 1.0/1.0 C 37. In the association rules method, a lift ratio of _________ indicated that the antecedent and consequent of a rule have no relationship beyond that of chance. A) 0 B) 1 C) ≤ 0 D) ≤ 1 1.0/1.0 B 38. In the association rules method, the most common procedure for generating frequent item sets is _________. A) the Apriori algorithm B) the Gini Index C) the simplex method D) recursive partitioning 1.0/1.0 A 39. Which of the following statements is true about affinity analysis? A) It is a supervised method. B) Variables must be normalized prior to analysis. C) The primary result of the analysis is an equation that can be used for prediction. D) None of the above. 1.0/1.0 D 40. Market basket analysis is commonly used in _________ systems. A) election polling B) recommender C) inventory control D) poulation demographic 1.0/1.0 B [Show More]
Last updated: 1 year ago
Preview 1 out of 36 pages
Instant download

Buy this document to get the full access instantly
Instant Download Access after purchase
Add to cartInstant download
Reviews( 0 )
Document information
Connected school, study & course
About the document
Uploaded On
Sep 22, 2020
Number of pages
36
Written in

Additional information
This document has been written for:
Uploaded
Sep 22, 2020
Downloads
0
Views
73