Information Technology > QUESTIONS & ANSWERS > ` CIS 450/550 Database and Information Systems Actual Midterm 2 with Answers . - University of Penn (All)
` CIS 450/550 Database and Information Systems Actual Midterm 2 with Answers . - University of Pennsylvania
Document Content and Description Below
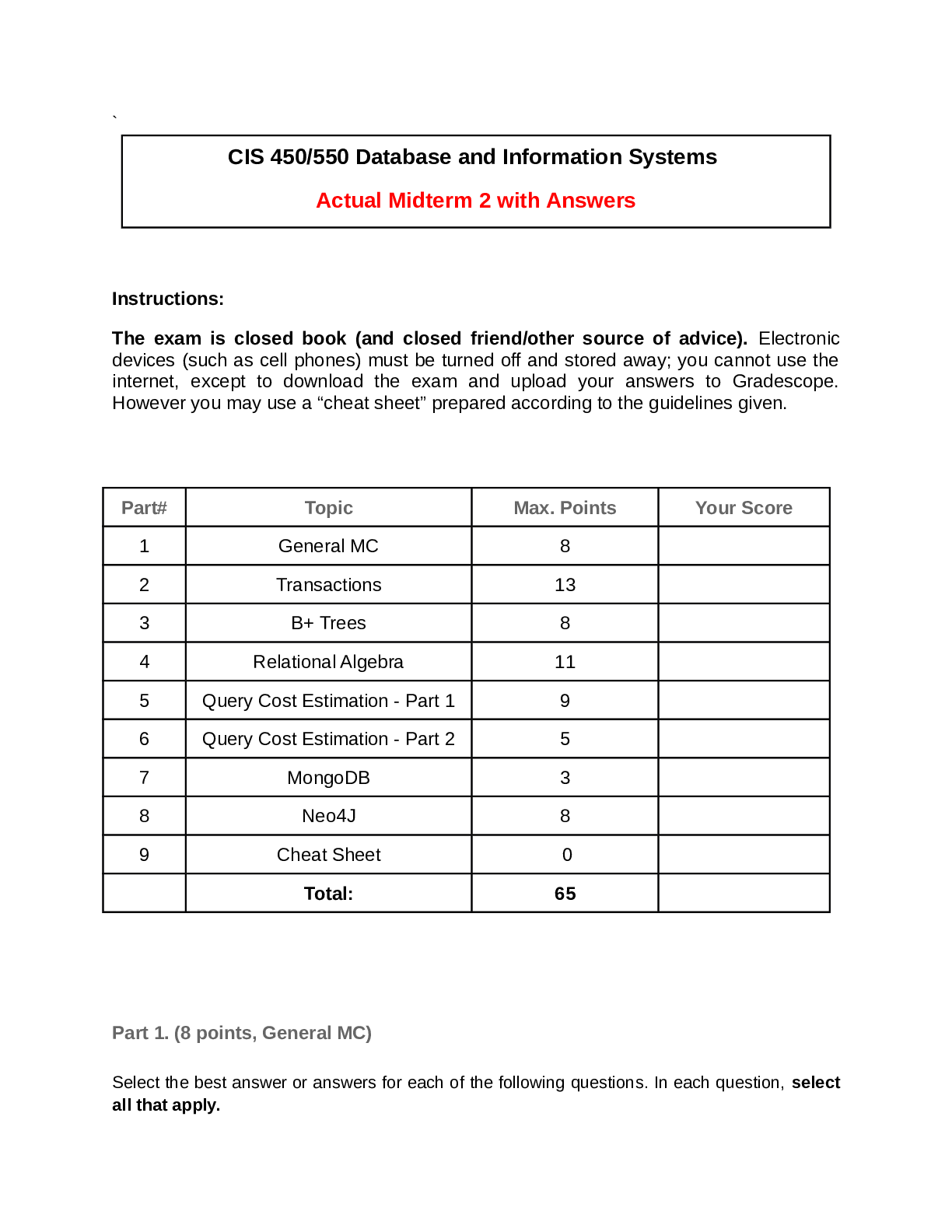
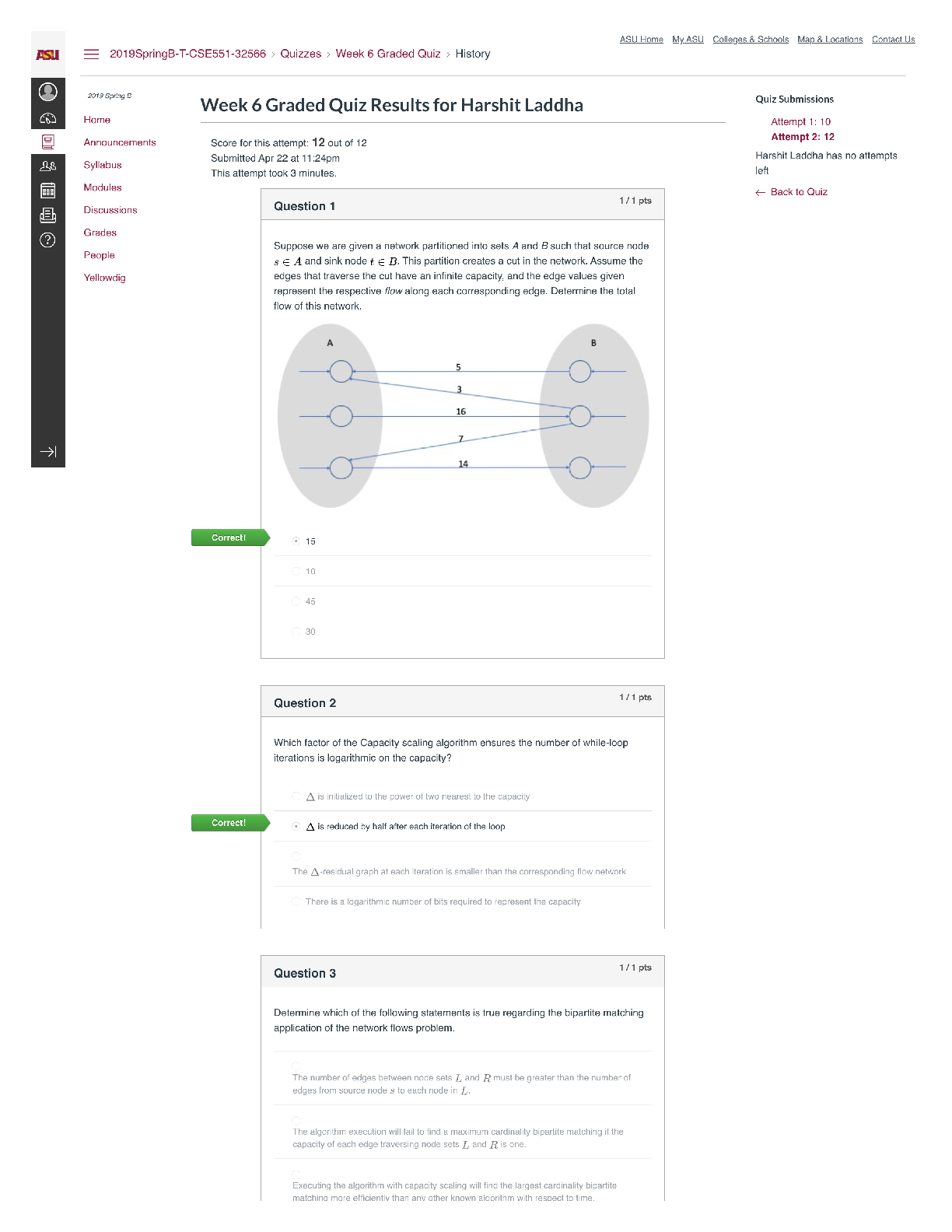
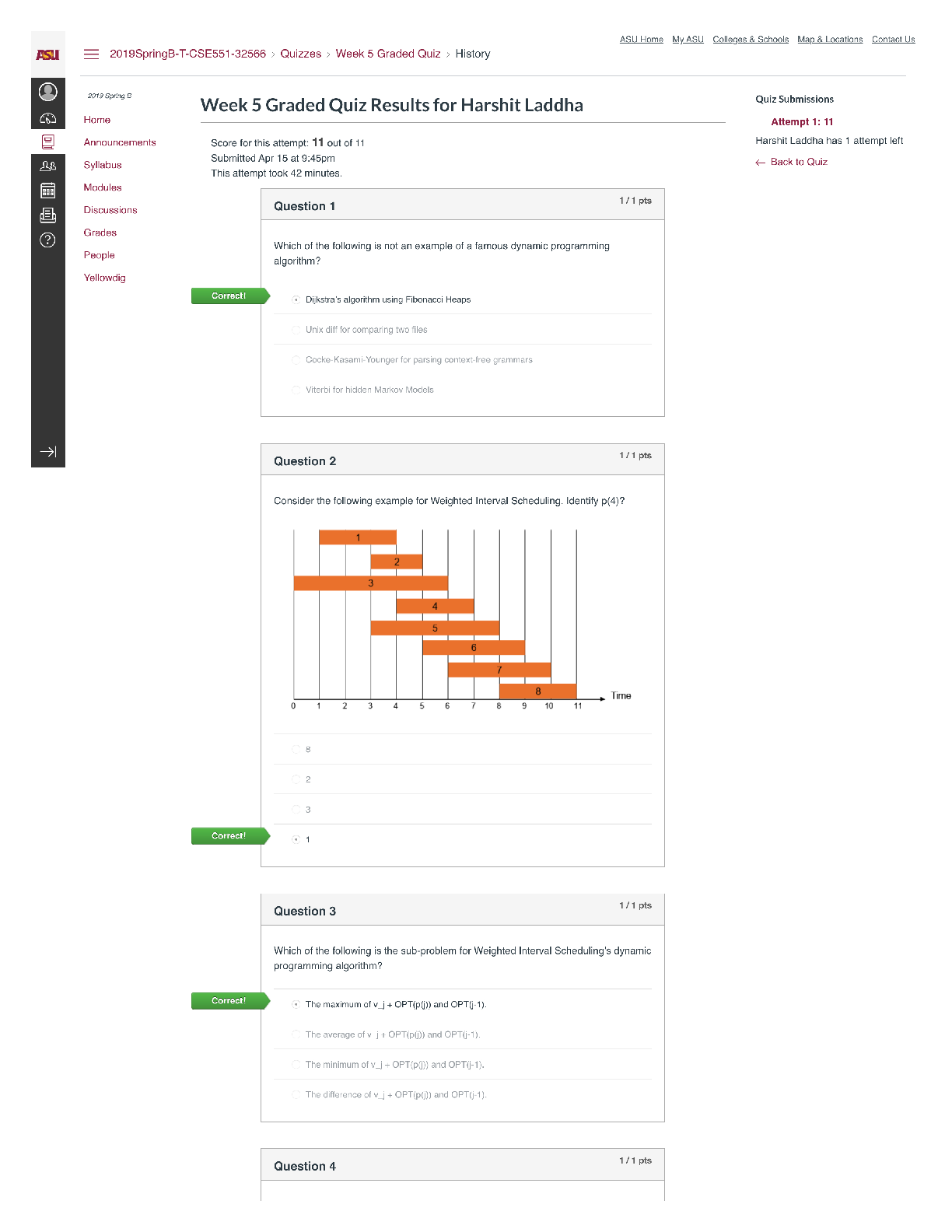
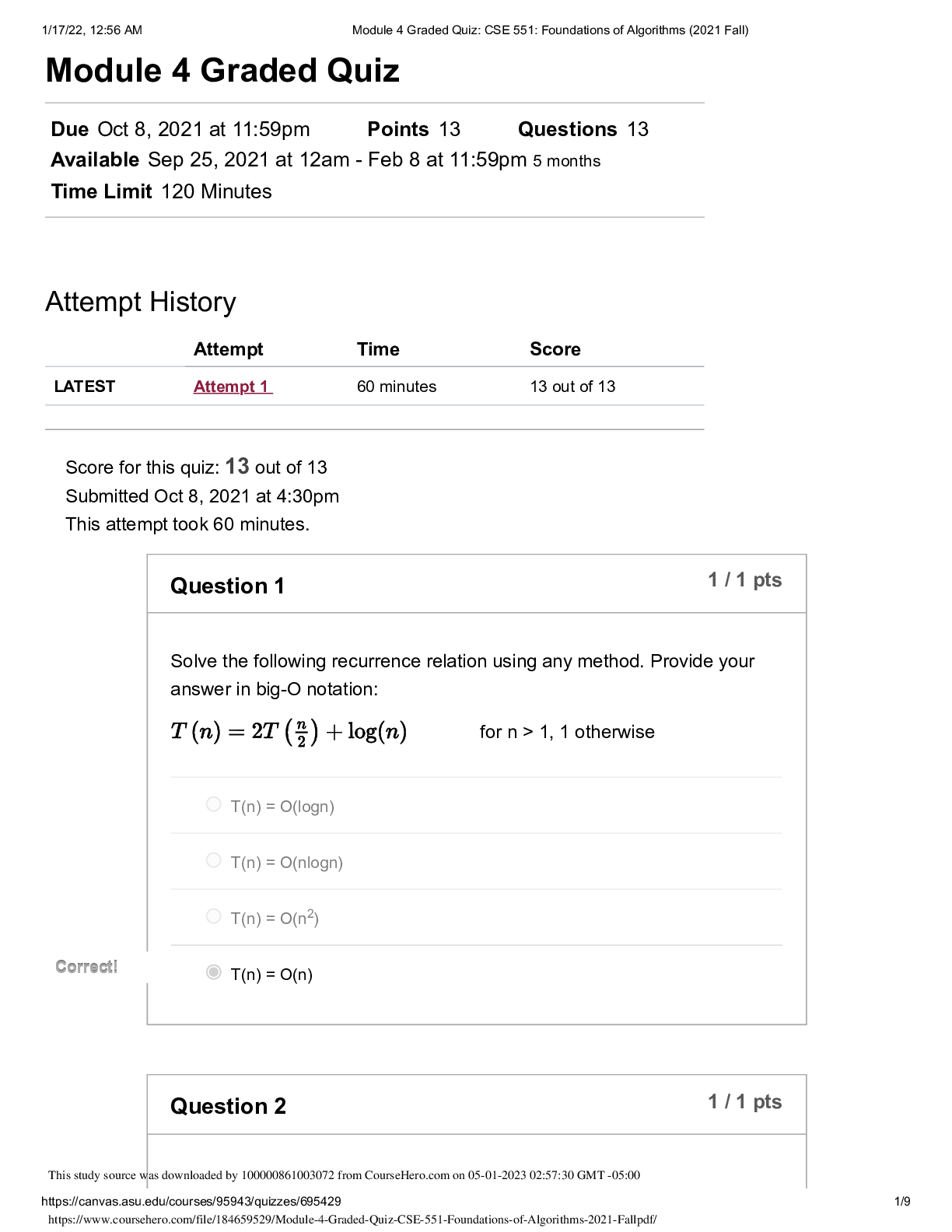
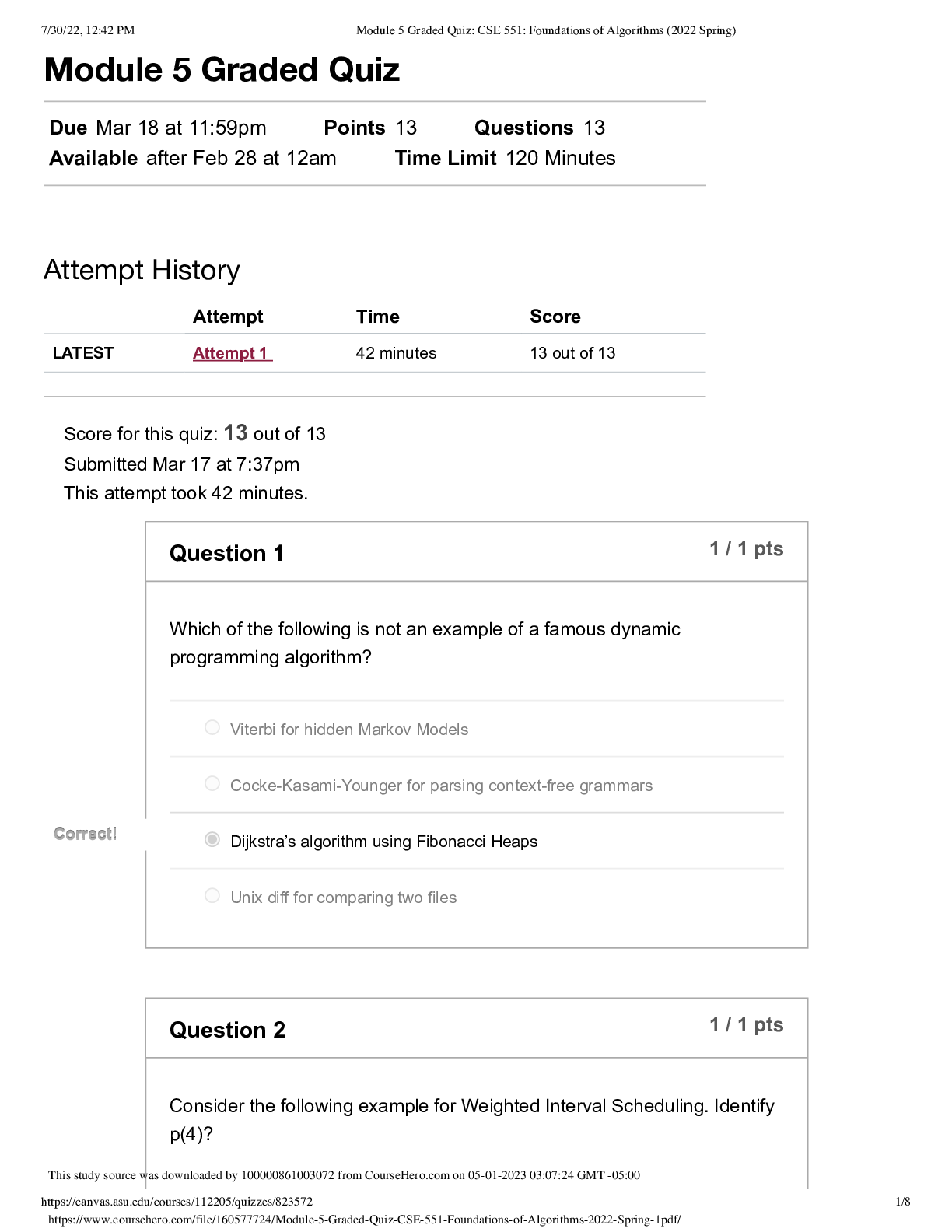
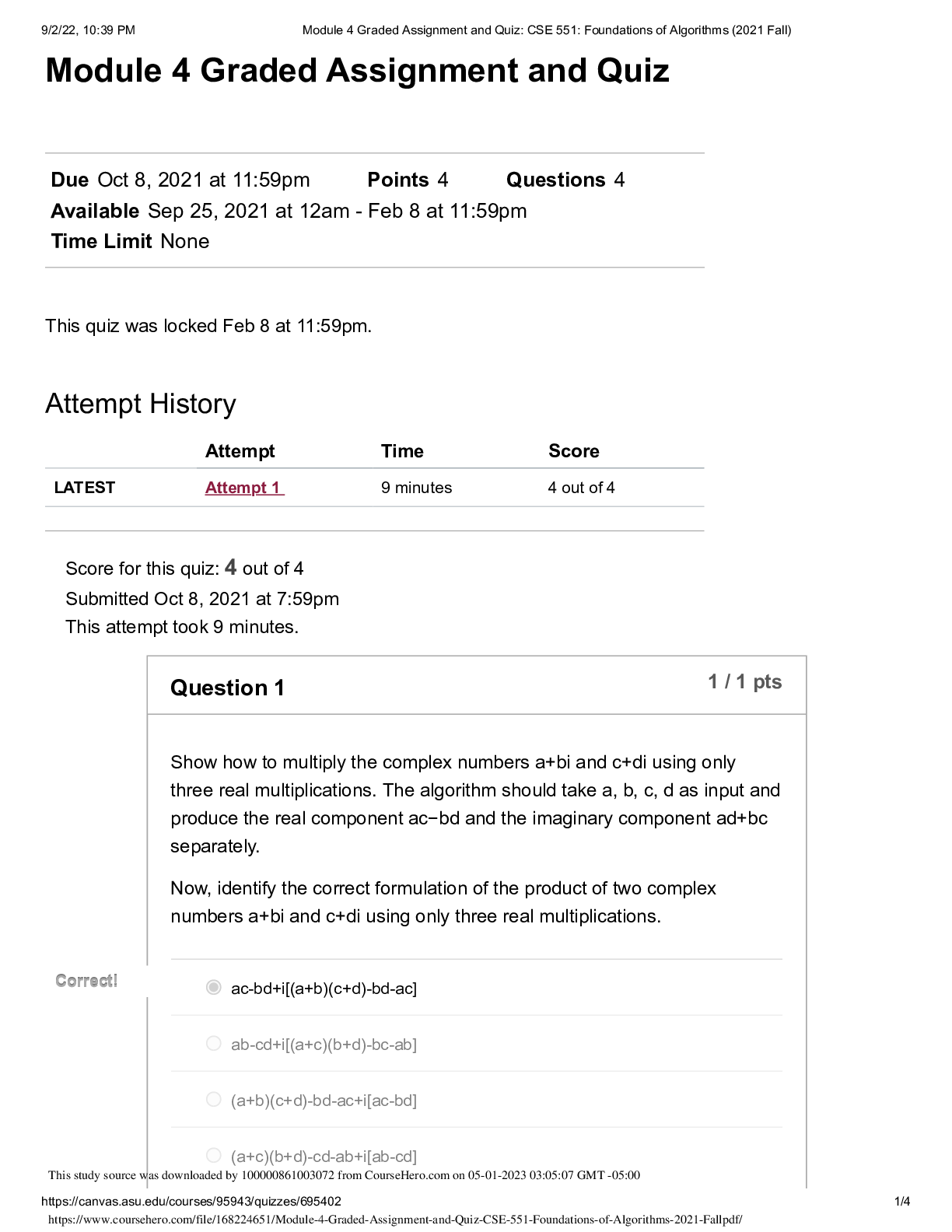
` CIS 450/550 Database and Information Systems Actual Midterm 2 with Answers The exam is closed book (and closed friend/other source of advice). Part 1. (8 points, General MC) Select the bes... t answer or answers for each of the following questions. In each question, select all that apply. 1. (2 points) When estimating the cost of a join implementation in Block Nested Loop Join and Merge Join, what is typically being counted? a. The number of comparisons performed in main memory. b. The estimated time it takes to retrieve all pages accessed, including the seek time, rotational delay and transfer time. c. The number of pages moved between main memory and disk. d. All of the above. 2. (2 points) State for each of the below whether it best represents a characteristic of an RDBMS (relational database system) or MongoDB (NoSQL database system). a. More flexible schema: MongoDB b. Stronger consistency guarantees: RDBMS c. Supports storage for hierarchical data: MongoDB d. Data must fit on single machine: RDBMS e. Queries are optimized for joins: RDBMS 3. (2 points) Suppose a DBMS ensures “legal” schedules (i.e. never grants any conflicting locks), and requires that all read-write transactions be well-formed and two-phase. However, the DBMS allows read-only transactions to execute without acquiring any locks. Which of the following is true? a. All executions are guaranteed to be serializable. b. All executions which include a read-only transaction are not serializable. c. All executions which include only read-write transactions (i.e. no read-only transactions) are serializable. d. All executions which include only read-only transactions (i.e. no read-write transactions) are conflict-serializable. 4. (2 points) Suppose there is a B+ index on [A, B, C] for R(A,B,C,D). For which of the following selections is the index useful? A. C=12 B. A=15 ⋀ D>3 C. B>10 ⋀ A>5 D. C=12 ANSWER: B, C ⋀ B > 10 Part 2. (13 points, Transactions) Consider the following execution E1 of transaction T1 (column 2), in which the time of each action is shown in column 1. Time T1 1 SLOCK(B) 2 XLOCK(A) 3 4 5 READ(B) 6 REL(B) 7 8 WRITE(A) 9 10 COMMIT REL(A) 11 For the following, consider each question independent of the questions that precede it. 1. (2 points) At time 3, transaction T2 requests an SLOCK(B). What is the earliest time in E1 that the request can be granted in a legal schedule? 2. (2 points) Is T1 a two-phased transaction in E1? Is it strict? Explain your answer. Now, consider the following schedule E2, unrelated to E1 T1 : R1(A), W1(A), R1(B), R1(C), W1(C) T2 : R2(A), R2(B), R2(C) T3 : R3(B), W3(C) are executed in the following schedule, where lock acquisitions (Si for shared lock, Xi for exclusive lock) and releases (RELi) are given, with subscripts i indicating the transaction performing the operation: S : X1(A), S1(B), R1(A), W1(A), R2(A), R1(B), S3(B), R3(B), R2(B), REL1(B), X1(C), R1(C), W1(C), R2(C), REL1(A, C), commit1, X3(C), W3(C), commit3, REL3(B, C) 3. (2 points) In S, is T1 two-phase? Why or why not? 4. (5 points) S : X1(A), S1(B), R1(A), W1(A), R2(A), R1(B), S3(B), R3(B), R2(B), REL1(B), X1(C), R1(C), W1(C), R2(C), REL1(A, C), commit1, X3(C), W3(C), commit3, REL3(B, C) Draw the precedence graph for this execution. Is S serializable? Why or why not? 5. (2 points) S : X1(A), S1(B), R1(A), W1(A), R2(A), R1(B), S3(B), R3(B), R2(B), REL1(B), X1(C), R1(C), W1(C), R2(C), REL1(A, C), commit1, X3(C), W3(C), commit3, REL3(B, C) What isolation levels are T1, T2 and T3 using in S? Explain your answer. Part 3. (8 points, B+ Trees) Consider a relation Customer(ID, name, age, shoesize) with a B+ tree index on age. The minimum capacity of a data entry page is 2 entries; the minimum capacity of an index page is 2 pointers/1 key value. Leaf nodes (data entry pages) point to data pages; each pointer represents a record ID (RID). A data page can store upto 3 data records. (a) (4 points) Write the key value index entries for the root and the intermediate nodes (index entries) in the tree above. (b) (2 points) The above index uses (select one choice): 1. Alternative 1 2. Alternative 2 3. Alternative 3 4. None of them (c) (2 points) The above index is (select one choice): 1. Unclustered Dense 2. Clustered Sparse 3. Clustered Dense 4. Unclustered Sparse Part 4. (11 points, Relational Algebra) For full credit, in all questions below, use ⋈ (natural join) whenever possible as opposed to cross product or ⋈θ (join on condition θ). Further, if R(A,B) and S(B,C) are joined as R ⋈ S, assume that the result has columns named A,B,C. Answer questions (a)-(d) below with respect to the following relational schema. Assume that Restaurant.zip references Place.zip and Serves.name references Restaurant.name. Restaurant name cuisine zipSway Thai 78745 Dandelion English 19103 Cole’s French 90014 ... ... ... Serves name mealSway lunch Dandelion dinner Cole’s dinner ... ... Place zip city78745 Austin19103 Philadelphia90014 LosAngeles ... ... (a) (4 points) Write a relational algebra query that returns the cuisines of restaurants that serve dinner in Austin. Use parentheses as much as possible for readability. (b) (4 points) Optimize the query you wrote in question (b) above as much as possible so that no intermediate relation contains unnecessary rows or columns. If your answer to that question is already in this form, then just answer “ditto” to this question. (c) (3 points) What does the following relational algebra query do? πcuisine ((πcuisine (Restaurant) X πzip (Place)) ー πcuisine, zip(Restaurant)) Part 5 (9 points, Join Cost Estimation) You are given the following statistics: • R has 100,000 tuples on 1,000 pages (100 tuples/page) • S has 10,000 tuples on 500 pages (20 tuples/page) • There are 52 buffers (a) (4 points) Give the best cost of executing the join of R and S using Block Nested Loop Join. You should consider both orders, R join S and S join R. (b) (5 points) Assume that R is already sorted on the join key, but that S is not. What is the cost of using a Sort-Merge Join? Recall: ceiling(log_N(M)) = 1 if 1 < M <= N. Part 6 (5 points, Select/Project Cost Estimation) (a) (5 points) As before: ● The query Q is: SELECT B, C FROM R WHERE A=1; ● R(A, B, C, D) has 100,000 tuples on 1,000 pages (100 tuples/page) ● Each attribute of R is the same size ● There are 500 distinct values in the domain of A (call them 1, 2, ..., 500) , each of which is equally likely to occur in a tuple of R ● There are 10 buffers R is a hashed file on the key A. The hash function is h(k)=k. Describe 1) how query Q is evaluated, and 2) what the cost is. You can assume that the bucket directory fits in memory. Part 7. (10 points, MongoDB and Map Reduce) Suppose we have a collection called movies whose documents have a structure similar to the following: myMovie={ _id: 1, title: “Pulp Fiction”, year: 1994, score: 94, director: {last: “Tarantino”, first: “Quentin”}, writers: [{last: “Tarantino”, first: “Quentin”}, {last: “Avary”, first: “Avary”}], genres: [“crime”, “drama”], actors: [{last: “Travolta”, first: “John”}, {last: “Thurman”, first: “Uma”}, … ] } (a) (3 points) Write a query which returns the title of every movie with actor John Travolta (among other possible actors) appearing in 1994. Do not return _id. Part 8. (8 points, Neo4J) Consider the nodes and relationships created by the Neo4j Cypher Code below: CREATE (you:Person {name:"You", age:20}) -[:WORKED_WITH]-> (neo:Database {name:"Neo4j" }), (you) -[:WORKED_WITH]-> (sql:Database {name:"Sql"}), (you) -[:WORKED_WITH]-> (mongo:Database {name:"Mongo"}), (amanda:Person{name:"Amanda", age:30}) -[:WORKED_WITH]-> (neo), (amanda) -[:WORKED_WITH]-> (mongo), (johan:Person{name:"Johan", age:18}) -[:WORKED_WITH]-> (neo), (johan) - [:WORKED_WITH]-> (sql), (johan) -[:WORKED_WITH]-> (mongo), (johan) -[:WORKED_WITH]-> (xml:Database {name:"Xml"}), (julia:Person {name:"Julia", age:25}) -[:WORKED_WITH]-> (sql), (andrew:Person {name:"Andrew", age:21}) -[:WORKED_WITH]-> (neo), (you) -[:KNOWS]-> (johan), (you) -[:KNOWS]-> (julia), (julia) -[:KNOWS]-> (anna:Person {name:"Anna", age:20}) (a) (2 points) Return the names of people whose age is greater than 20. (b) (3 points) Return the number of people you know. (c) (3 points) Return the persons you and Anna both know. Part 9 (3 points, Cheat Sheet) Please upload your cheatsheet here. It can be either a PDF file, an image, or a Word document. [Show More]
Last updated: 1 year ago
Preview 1 out of 10 pages
Reviews( 0 )
Document information
Connected school, study & course
About the document
Uploaded On
Apr 29, 2023
Number of pages
10
Written in

Additional information
This document has been written for:
Uploaded
Apr 29, 2023
Downloads
0
Views
58















.png)




-1.png)

