Engineering > QUESTIONS & ANSWERS > ISYE - 6501 Homework 2 Latest Update (All)
ISYE - 6501 Homework 2 Latest Update
Document Content and Description Below
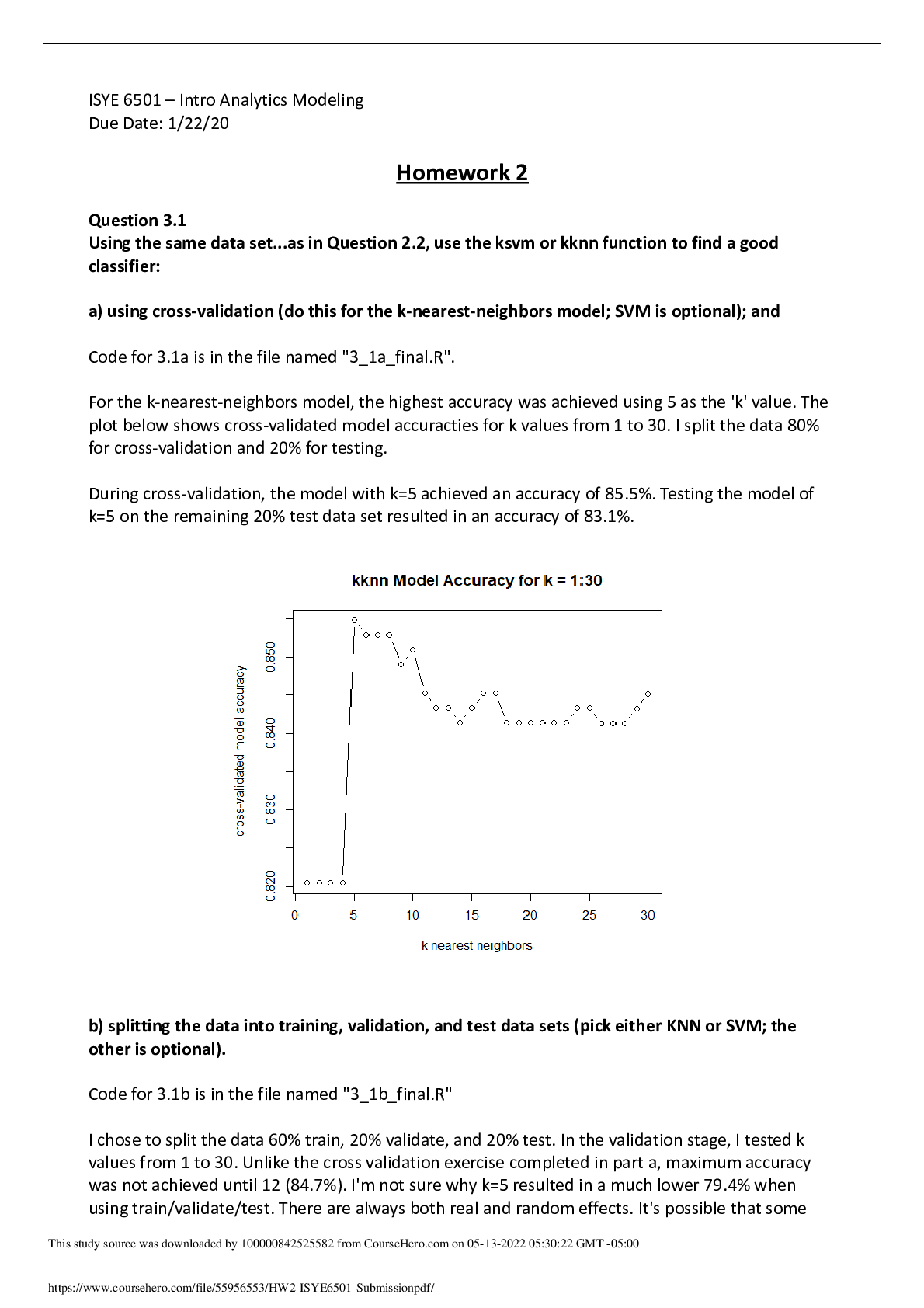
ISYE - 6501 Homework 2 Due Date: Thursday, September 3rd, 2020 Contents 1 ISYE - 6501 Homework 2 2 2 Homework Analysis 2 2.1 Analysis 3.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .... . . . . . . . . . . . . . . . . . 2 2.2 Analysis 4.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.3 Analysis 4.2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1 1 ISYE - 6501 Homework 2 This document contains my analysis for ISYE - 6501 Homework 2 which is due on Thursday, September 3rd, 2020. Enjoy! 2 Homework Analysis 2.1 Analysis 3.1 Q: Using the same data set (credit_card_data.txt or credit_card_data-headers.txt) as in Question 2.2, use the ksvm or kknn function to find a good classifier. (a) using cross-validation (do this for the k-nearest-neighbors model; SVM is optional) RESULTS By using cross-validation at 10 folds on a k-nearest-neighbors (KNN) model, at k=15 with a rectangular kernel, we were able to achieve an accuracy score of roughly 85% (85.47009%). This means that 85 out of every 100 applicants is predicted correct! THE CODE: # needed library rm(list=ls()) library(kknn) library(dplyr) set.seed(12345) # read data into R data_path <- "data 3.1/" data_filename <- "credit_card_data-headers.txt" credit_data <- read.delim(paste0(data_path, data_filename), header=TRUE) # train-valid-test-split sample_split <- sample(1:3, size=nrow(credit_data), prob=c(0.7,0.15,0.15), replace = TRUE) train_credit <- credit_data[sample_split==1,] valid_credit <- credit_data[sample_split==2,] test_credit <- credit_data[sample_split==3,] # training our model train_model <- train.kknn(R1~., train_credit, kmax=100, scale=TRUE, kcv=10, kernel=c("rectangular", "triangular", "epanechnikov", "gaussian", "rank", "optimal"), kpar=list()) train_model ## ## Call: 2 ## train.kknn(formula = R1 ~ ., data = train_credit, kmax = 100, kernel = c("rectangular", "triangul## ## Type of response variable: continuous ## minimal mean absolute error: 0.221968 ## Minimal mean squared error: 0.1175795 ## Best kernel: rectangular ## Best k: 15 Using cross-validation at 10 folds, we can see that the best kernel for our model is rectangular with a k of 15. Now that we have the best parameters for our model, let’s use them to train our validation data. # validating our model valid_model <- train.kknn(R1~., valid_credit, ks=15, kernel="rectangular", scale=TRUE, kpar=list()) valid_pred <- round(predict(valid_model, valid_credit)) accuracy_score <- sum(valid_pred == valid_credit[,11]) / nrow(valid_credit) [Show More]
Last updated: 1 year ago
Preview 1 out of 9 pages


Reviews( 0 )
Document information
Connected school, study & course
About the document
Uploaded On
May 19, 2022
Number of pages
9
Written in

Additional information
This document has been written for:
Uploaded
May 19, 2022
Downloads
0
Views
157
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)

.png)
.png)






.png)
.png)









